こんにちは.閃光のハサウェイが配信開始されたので早速視聴しました.メッサーがいいですね.
前回もXDP関連の話題でしたが,今回はXDPに入門します. XDPを学習する際のロードマップやつまりどころの解消になればと思います.
# 2023-12-30 加筆
本記事を公開して約 2 年が経過しました. この加筆で古くなってしまった情報を修正しています. 差分は このブログの Github の PR (opens new window) を見てください.
この 2 年間で eBPF 及び XDP への注目はさらに高まったように感じます. 取得できる情報も充実してきました. 特に O'reilly より発売された 入門 eBPF (opens new window)(原書: Learning eBPF (opens new window)) は非常に充実した内容になっています. 日本語でこれらの情報に触れられるようになったことは大変ありがたいです.
2023 年は個人的にも XDP に関して新たに発展的なコンテンツを作成しました.
そちらも触っていただければと思います.

# XDP
XDPとはeXpress Data Pathの略でLinuxカーネル内で動作するeBPFベースの高性能なパケット処理技術です. 制限のあるC言語で記述したプログラムをBPFバイトコードにコンパイルし,NICにアタッチすることでカーネルのプロトコルスタックより手前でパケット処理を行うことができます. XDPには以下のようなメリットがあります.
- カーネルを修正することなく柔軟にパケット処理機能を実装することができる
- 特別なハードウェアを準備することなく利用することができる
- 高速にパケットを処理することができる
- 既存のTCP/IPスタックを置き換えることなく協調して動作させることができる
# ユースケース
XDPのユースケースとして以下のようなものがあります.
- DDos攻撃の軽減
- L4ロードバランサ
- NAT
- Kubernetes Networking(LB, Conntrack, Network policy)
- Router
# アーキテクチャ(仕組み)
XDPプログラムはC言語として記述し,BPFバイトコードにコンパイルします. また,BPF Verifierによりメモリアクセスやループなどを静的に検査してNICにロードします.
プログラムがアタッチされるとパケットの着信の度にNICのデバイスドライバ内でフックされてプログラムが実行されます.
そのためsk_buffが生成されるより前の段階でパケットを編集することができます.
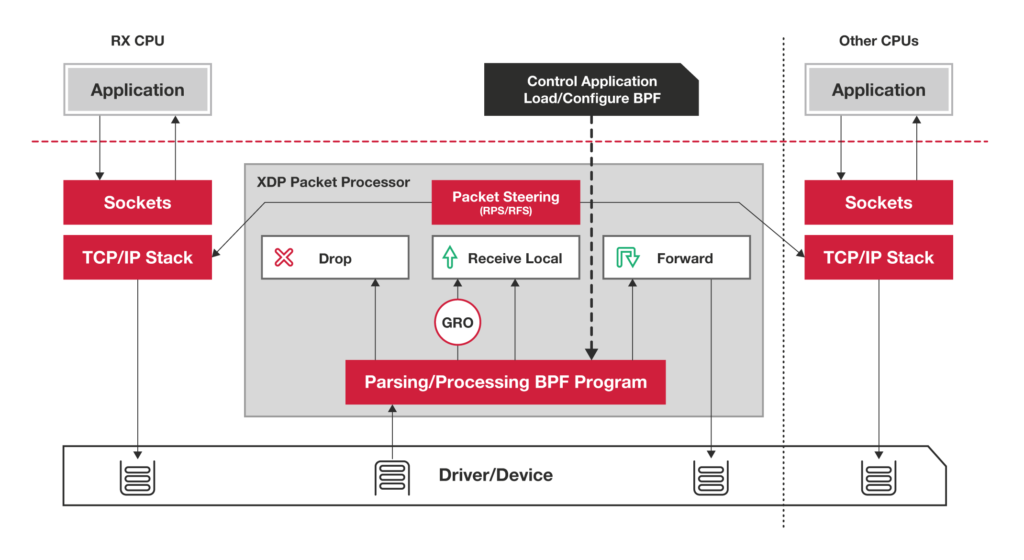
# XDP Actions
XDPプログラムはそのXDP Actions(終了コード)によってパケットを制御します. サポートされているXDP Actionsは以下です.
- XDP_PASS
- パケットをOSのプロトコルスタックに流す.
- XDP_DROP
- パケットをドロップする.
- XDP_TX
- パケットを受信したNICから送出する.
- XDP_ABORTED
- BPFのエラーを返す際に使用する.パケットはドロップする.
- XDP_REDIRECT
- 受信したパケットを
DEVMAPに登録されたNICから送出する.
- 受信したパケットを
# BPF Map
BPFプログラムはカーネル内にロードされます.BPFプログラム(カーネル空間)とユーザー空間でデータをやり取りする手段としてBPFマップがあります.
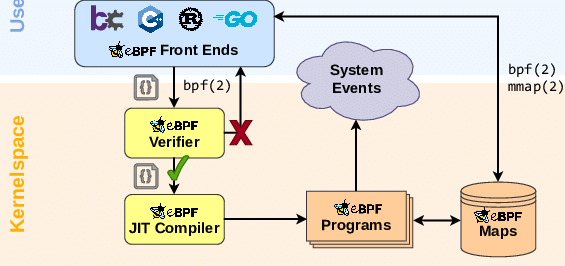
BPFマップは任意の型のKey-Value連想配列です.bpfシステムコールによって作成,値の追加,削除,参照などが行われます.
# BPF Map Type
BPFマップはその用途に対して25種類のタイプが存在します. ユーザーは自身の用途に合わせたマップを使用することができます. 各タイプは以下のようになっています.
- BPF_MAP_TYPE_UNSPEC
- BPF_MAP_TYPE_HASH
- 単純なハッシュ.
- BPF_MAP_TYPE_ARRAY
- 単純な配列.要素の削除はできない
- BPF_MAP_TYPE_PROG_ARRAY
tail_call(詳しくは前エントリ(Goのcilium/ebpfでXdpcapを使う (opens new window)))のジャンプテーブルとして使用される配列
- BPF_MAP_TYPE_PERF_EVENT_ARRAY
bpf_perf_event_output()の結果が保持される.ユーザースペースのプログラムはそれをpoll()してあげる.
- BPF_MAP_TYPE_PERCPU_HASH
- CPUごとに割り当てられるハッシュ.
- BPF_MAP_TYPE_PERCPU_ARRAY
- CPUごとに割り当てられた配列.
- BPF_MAP_TYPE_STACK_TRACE
- BPF_MAP_TYPE_CGROUP_ARRAY
- BPF_MAP_TYPE_LRU_HASH
- LRUハッシュ
- BPF_MAP_TYPE_LRU_PERCPU_HASH
- CPUごとのLRUハッシュ
- BPF_MAP_TYPE_LPM_TRIE
- longest-prefixマッチをサポートしたマップ.ルートテーブルなどを作る際に使用する.
- BPF_MAP_TYPE_ARRAY_OF_MAPS
- BPF_MAP_TYPE_HASH_OF_MAPS
- BPF_MAP_TYPE_DEVMAP
bpf_redirect()に使用する.NIC間のリダイレクト用.
- BPF_MAP_TYPE_SOCKMAP
- BPF_MAP_TYPE_CPUMAP
- BPF_MAP_TYPE_XSKMAP
- BPF_MAP_TYPE_SOCKHASH
- BPF_MAP_TYPE_CGROUP_STORAGE
- BPF_MAP_TYPE_REUSEPORT_SOCKARRAY
- BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE
- BPF_MAP_TYPE_QUEUE
- BPF_MAP_TYPE_STACK
- BPF_MAP_TYPE_SK_STORAGE
たくさんあります. しかし,BPF(XDP)を使う際によく使うマップはそんなに種類はなく,太字にしているものくらいだと思います.
- BPF In Depth: Communicating with Userspace (opens new window)
- bpf(2) - Linux manual page - man7.org (opens new window)
# ヘルパー関数
BPFマップの作成や参照,更新はbpfシステムコール (opens new window)を呼び出すことで行われます. 定義は以下です.
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
linux/bpf.hをインクルードすると使えるとのことですが,通常の環境では定義がありません.
そのためbpfシステムコールを直で使うのは結構大変です.
そこで,BPFマップの扱いを簡潔にするヘルパー関数 (opens new window)が用意されています. マップの操作に限らず様々なヘルパー関数が定義されています. ここでは頻繁に使用する関数のみ見ていきます.他の関数が気になる方はman page (opens new window)をのぞいてみてください.
# マップ関連
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)- keyに対応するvalueを探す
- 値のポインタがNULLかチェックが必要
long bpf_map_update_elem(struct bpf_map *map, const void *key, const void *value, u64 flags)- keyに対応するvalueの値を更新する
- flagsに渡す値によって値がすでに存在している場合の挙動などを指定する
flags = 0で新規に値を追加できる
long bpf_map_delete_elem(struct bpf_map *map, const void *key)- keyに対応するエントリを削除する
# デバッグ
long bpf_trace_printk(const char *fmt, u32 fmt_size, ...)- デバッグのためにメッセージを出力する
/sys/kernel/debug/tracing/trace_pipeに出力されるのでcatなどで読む
# XDPで使う
long bpf_fib_lookup(void *ctx, struct bpf_fib_lookup *params, int plen, u32 flags)- FIB(Forwarding Information Base)(ルートテーブル)を参照することができる
- bpf_fib_lookup (opens new window)という構造体を通してルートテーブルを参照して結果を得る
long bpf_xdp_adjust_head(struct xdp_buff *xdp_md, int delta)xdp_md->dataで得られるパケットの先頭をずらすことができる- encap/decapに使用する
# Generic XDP
前項までで述べたようにXDPはNICのデバイスドライバレベルでパケットを処理します.
つまり,XDPが有効なNICでなければ使用することができません.
しかし,このような制限があると気軽にXDPを試すことができません.
そこでLinux KernelにはGeneric XDPという機能がサポートされています.
このGeneric XDPはXDPの強みである高速さを犠牲にしてsk_buffの生成後にXDPプログラムを実行することができるようにしています.
そのため,NICのサポートの有無を気にすることなくXDPを試すことができます.
入門段階ではほぼすべてのケースでGeneric XDPを使用することとなるため以降のサンプルではGeneric XDPを使用します.
Generic XDPの話題はこちら (opens new window)の記事が詳しいので背景など気になる方はご覧ください.
# 実験環境
本記事での実験環境は以下のようになっています.
- AWS EC2 instance t3.large
- kernel version
- 5.11.0-1019-aws
- architecture
- x86_64
- NIC
- Elastic Network Adaptor(ENA)
- os
- Ubuntu 20.04.3 LTS
- clang
- 10.0.0-4ubuntu
- iproute2
- iproute2-ss200127
- go
- go1.16.7 linux/amd64
# 使い方
XDPの使い方を紹介します. XDPプログラムを実行するまでの手順は以下です.
- XDPが有効なカーネルか確認し依存関係を解決する
- C言語(制限付き)でXDPプログラムを記述する
clangでBPFバイトコードにコンパイル- カーネルにロードする
それぞれを詳しく見ていきましょう.
# XDPが有効なカーネルであるか確認, 依存関係の解決
# XDPが有効なカーネルか確認
まずはカーネルのバージョンを確認します.
Generic XDPが使えるのは4.12以上です.
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_XDP_SOCKETS=y
2
3
4
5
これらの設定は以下のコマンドで確認します.
$ grep -i CONFIG_BPF /boot/config-$(uname -r)
$ grep -i CONFIG_XDP_SOCKETS /boot/config-$(uname -r)
2
その他詳しい機能のサポートバージョンなどはHow to compile a kernel with XDP support (opens new window)をご覧ください.
# 依存関係の解決
依存関係のセットアップはxdp tutorialのSetup dependencies (opens new window)をご覧ください. 各ディストリビューションのインストールについて記載されています.
# NICの設定
Generic XDPを使用する場合はあまり気にする必要はないですがNative XDP(NICに実際にロードするXDP)を使用する場合mtuやqueueの問題でロードが失敗する可能性があります.
本実験環境では以下のコマンドで設定を変更することでNICにXDPをロードすることができました.
$ sudo ip link set dev ens5 mtu 3498
$ sudo ethtool -L ens5 combined 1
2
# C言語(制限付き)でプログラムを記述する
C言語でプログラムを記述しますがBPFのプログラムは様々な制約があります. 主な制約は以下となっています.
- 命令数の制限
- カーネルバージョン5.3以上で1M
- ループ制限
- 無限ループは禁止
- 5.2から有限ループは可能
- 到達不可能な命令があってはいけない
- 有効なメモリにのみアクセスできる
- メモリが有効なものかチェックする必要がある
実際にプログラムを書く際の作法は実践-BPF(XDP)用C言語のお作法の項に記述しています.
BPFプログラムの制限に関する資料は以下を参照してください.
# clangでBPFバイトコードにコンパイルする
example.cをexample.oに吐き出すコマンドは以下のような感じです.
$ clang -O2 -target bpf -c example.c -o example.o
# カーネルにロードする
コンパイルして生成されたELFファイルをカーネルにロードするすることによってXDPが実行されます. ロードする方法はいくつか存在します.
# iproute2
最も気軽に利用できるロード方法はiproute2を利用することです.
iproute2を利用する場合のロードは次のようにします.
$ ip link set dev ens5 xdp obj example.o
ロード後にNICの情報を見てみると以下のようにxdpプログラムがロードされています.
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 3498 xdp qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 0e:66:45:0d:d9:b9 brd ff:ff:ff:ff:ff:ff
prog/xdp id 67
2
3
XDPプログラムを外す場合は以下のコマンドを実行します.
$ sudo ip link set dev ens5 xdp off
# プログラムからロードする
BPFマップを利用するような複雑なXDPプログラムを実行したい場合,コントロールプレーンとしてプログラムを書く必要があります. コントロールプレーンはどの言語でも特に問題ありません. 本記事ではコントロールプレーンのプログラムにはGo言語を使用します.
# 実践
本項ではXDPプログラムを実際に書いて動かしてみます. Go言語でXDPのコントロールプレーンを記述するパッケージがいくつかあります.
スターの数や開発状況などから見てもcilium/ebpfがデファクトといってよいと思います.
これからGo+XDPで開発を行うのであればcilium/ebpfを使うのがよいでしょう.
一方でdropbox/goebpfはexamplesにxdpのサンプルがいくつかあり,基本的なプログラムを学ぶには非常によいと思います.
また,作りがシンプルなのでとっかかりやすいのではないかと思います.
iovisor/gobpfは使用したことがないのでわかりませんがCGOという話なのであまりお勧めとは言えません.
いくつかライブラリを紹介しましたが本記事ではcilium/ebpfを使用してプログラムを記述します.
今回の実践編のサンプルコードは以下のリポジトリにあります.
 (opens new window)
(opens new window)
2023/12/30 現在,cilium/ebpfの更新によりコントロールプレーンのコードも古くなってしまっています. 現在のコントロールプレーンのコードは以下のリポジトリ(冒頭に挙げたコンテンツのリポジトリ)を参照したほうが最新の情報に近いです.
# BPF(XDP)用C言語のお作法
BPFバイトコードにコンパイルするC言語は様々な制約があると述べました. 本項ではその制約について具体的な例を示します.
# 命令数の制約
カーネルバージョン5.3から命令数制限は1Mとなっているので現実的にこの制約が問題となることはないでしょう.
もし命令数制限を超えるBPFプログラムをロードしたいとき,複数のプログラムに分割,ロードするということになります.
これを実現するための手段としてbpf_tail_call(), BPF_MAP_TYPE_PROG_ARRAYが用意されています.
詳しいドキュメントはcilium document - tail-calls (opens new window)をご覧ください.
# 無限ループ禁止
無限ループは禁止ですが有限ループは可能です.
XDPではパケットの改変を行うのでチェックサムの計算を行う機会も多いです.
IPチェックサムを計算する関数を例示します.
このコードはbufsizeがいずれ必ず1以下となるので有効です.
static inline __u16 checksum(__u16 *buf, __u32 bufsize) {
__u32 sum = 0;
while (bufsize > 1) {
sum += *buf;
buf++;
bufsize -= 2;
}
if (bufsize == 1) {
sum += *(__u8 *)buf;
}
sum = (sum & 0xffff) + (sum >> 16);
sum = (sum & 0xffff) + (sum >> 16);
return ~sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 有効なメモリにのみアクセスする
BPFプログラムではアクセスしたいメモリが有効であるか明示的にチェックした後でしかアクセスできません. 頻出する有効メモリチェックを二つ示します.
# パケットのパース
ここでdataはNICから受け取ったデータの先頭のポインタ.data_endは末尾のポインタです.
etherというethernetヘッダ用変数のポインタにdataを代入してethernetヘッダをパースします.
このとき,ヘッダサイズがdata_endを超えている場合無効なメモリにアクセスすることとなるのでdata + sizeof(*ether) > data_endであることを明示的にチェックしなければなりません.
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *ether = data;
if (data + sizeof(*ether) > data_end) {
return XDP_ABORTED;
}
2
3
4
5
6
# BPFマップのlookup
BPFマップの参照は値が存在しなかった場合NULLとなります. そのため,参照結果がNULLでないことをチェックしてから値を使用しなければなりません.
__u32 *val = bpf_map_lookup_elem(&map, key);
if (!val) {
return XDP_PASS;
}
2
3
4
# 処理を関数に切り分けるときはinline展開する
XDPプログラム本体として実行される以外の自作関数はすべてinline展開される必要があります.
そのため,自作関数にはすべてstatic inlineをつけましょう.
無限ループ禁止で例示したchecksum()関数を参考にしてください.
# eBPF組み込み関数しか使えない
memset(), memcpy()といった関数はllvm組み込みの関数を使用することとなります.
__builtin_memset((dest), (chr), (n))
__builtin_memcpy((dest), (src), (n))
__builtin_memmove((dest), (src), (n))
2
3
とはいえ引数は変わらないので気を付けていれば大丈夫です.
# グローバル変数が使えない使える
グローバル変数は使用できません. 変わりに毎回BPFマップから値をとってくることとなります.
2019 年 にグローバル変数をサポートするコミット (opens new window)が作成されています. また,グローバル変数はカーネルバージョン 5.5 から使える (opens new window)ようです. 本記事執筆時点でも使えたようです. 誤情報を広めていました. 訂正します.
グローバル変数は内部的にはエントリ数 1 のマップが作成されているようです.
# 可変長引数を取れない
可変長引数をとる関数を作成・使用することができません.
例としてbpf_printk(fmt, ...)を見てみます.
bpf_printk()はbpf_trace_printk()を使いやすくラップした関数です.
定義は以下です.
#define bpf_printk(fmt, ...) \
({ \
char ____fmt[] = fmt; \
bpf_trace_printk(____fmt, sizeof(____fmt), ##__VA_ARGS__); \
})
2
3
4
5
以下のように文字列を含めた5つの引数をとらせてみます.
int test(struct xdp_md *ctx)
{
int a, b, c, d = 0;
bpf_printk("%d %d %d %d", a, b, c, d);
return XDP_PASS;
}
2
3
4
5
6
$ clang -O2 -target bpf -c example.c -o example.o
example.c:9:5: error: too many args to 0xb70290: i64 = Constant<6>
int test(struct xdp_md *ctx)
^
1 error generated.
2
3
4
5
コンパイルするとtoo many argsと怒られます.
これを4つ以下の引数にすると無事コンパイルは通ります.
MACアドレスなどをデバッグ出力したいときに非常に困りますが仕方ありません.気を付けましょう.
その他制約やコンパイル方法などは次のドキュメントが詳しいです.
# チュートリアル
この項ではチュートリアルとしてdropbox/goebpf/examples/xdp (opens new window)にあるサンプルをcilium/ebpfを用いて動かしてみるということを行います.
dropbox/goebpf/examples/xdp配下には
- packet_counter
- xdp_dump
- basic_firewall
- bpf_redirect_map
の4つのサンプルがあります. こちらのC言語で書かれたXDPプログラムは基本的にそのまま使用します.(一部変更しなければ動作しないものがあるため変更します.)
# 構成
まずディレクトリ構成について軽く述べます.
/header/配下にbpf.h, bpf_helpers.hを配置しています.これはBPFプログラムを記述するためのhelper関数などが定義されたヘッダファイルで,これらを使用することでBPFプログラム記述の負担が軽減されます.
今回配置しているのはdropbox/goebpf/に置いてあるものになっています.
様々なBPFプロジェクトが独自のヘッダファイルを使用している場合があり,微妙に定義が異なることもあるので注意してください.
各サンプルのディレクトリの中のbpf/配下にBPFプログラムを配置しています.
各サンプルのトップにはGoのプログラムが置いてあります.
ビルドなどはこのディレクトリで行います.
# ビルド
ビルドに必要なステップは二つです.
$ go generate
$ go build .
2
go generateによってbpf/配下のC言語のコードをBPFバイトコードにコンパイルしてGoで扱うためのコードを自動生成します.
これはbpf2go(github.com/cilium/ebpf/cmd/bpf2go (opens new window))というツールを使用しています.
main.goの中に//go:generateという感じで記述しておくことでコードを自動生成してくれます.
これが最初はとっつきにくいですが慣れると非常に便利です.
後は普通にビルドすることによってシングルバイナリとしてBPFのプログラムを扱うことができます.
# packet_counter
packet_counterは指定されたNICが受信したパケットをプロトコルごとにカウントするプログラムです.
main.goとbpf/xdp.cから構成されます.
それぞれに分けてみていきます.
# XDP
まずはXDPのコードから見ていきましょう.
最初はヘッダのインクルードと構造体の定義です.
bpf_helpers.hをインクルードします.
さらにパケットを表現する構造体を定義します.
しかし,これはlinux/if_ether.hやnetinet/ip.hなどを使用してもかまいません.
続いてBPFマップを定義します.
packet_counterではBPF_MAP_TYPE_PERCPU_ARRAYを定義しています.
// eBPF map to store IP proto counters (tcp, udp, etc)
BPF_MAP_DEF(protocols) = {
.map_type = BPF_MAP_TYPE_PERCPU_ARRAY,
.key_size = sizeof(__u32),
.value_size = sizeof(__u64),
.max_entries = 255,
};
BPF_MAP_ADD(protocols);
2
3
4
5
6
7
8
keyは4byte, valueは8byteで定義しています. 続いてXDP関数です.
SEC("xdp")
int packet_count(struct xdp_md *ctx) {
...
}
2
3
4
xdpというセクション名を割り当てた関数がパケットの受信の度に呼び出されることとなります.
この関数はxdp_mdという構造体を引数に取ります.
の構造体は受信したパケットなどの情報を保持したコンテキストです.
定義はheader/bpf_helpers.h (opens new window)にあり,以下のようになっています.
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
__u32 egress_ifindex; /* txq->dev->ifindex */
};
2
3
4
5
6
7
8
9
10
dataが受信したパケットデータの先頭のポインタ,data_endがそのパケットデータの末尾のポインタとなっています.
それではpacket_countの中身を見ていきましょう.
パケットデータの先頭,末尾のポインタを移動させながらパケットをパースするのでそのための変数data, data_endを定義します.
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
2
続いてethernetヘッダをパースします.
struct ethhdr *ether = data;
if (data + sizeof(*ether) > data_end) {
return XDP_ABORTED;
}
2
3
4
今回はIPv4プロトコルのみを扱うのでether->h_protoで分岐し,IPv4にマッチした場合のみ以下の処理を実行します.
dataをethernetヘッダのサイズ分ずらすことでIPv4パケットの先頭にポインタを合わせてパースします.
その後,先ほど定義したprotocolsマップからIPプロトコルタイプをキーとして値を取り出しインクリメントすることでパケットをカウントします.
if (ether->h_proto == 0x08U) { // htons(ETH_P_IP) -> 0x08U
data += sizeof(*ether);
struct iphdr *ip = data;
if (data + sizeof(*ip) > data_end) {
return XDP_ABORTED;
}
// Increase counter in "protocols" eBPF map
__u32 proto_index = ip->protocol;
__u64 *counter = bpf_map_lookup_elem(&protocols, &proto_index);
if (counter) {
(*counter)++;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
最後にパケットをカーネルに流します.
return XDP_PASS;
# Go
続いてコントロールプレーンのコードを見ていきます.
main.goに
//go:generate go run github.com/cilium/ebpf/cmd/bpf2go -cc clang XdpProg ./bpf/xdp.c -- -I../header
と記述することによってbpf2goをgo generateで使えるようにしています.
まずbpfプログラムとマップを保持する構造体を定義します.
type Collect struct {
Prog *ebpf.Program `ebpf:"packet_count"`
Protocols *ebpf.Map `ebpf:"protocols"`
}
2
3
4
それではmain関数の処理を見ていきましょう.
コマンドライン引数からXDPプログラムをアタッチするインターフェース名を受け取り,そのインターフェースの情報を取得する処理を最初に行っています.
インターフェース情報の取得などはvishvananda/netlink (opens new window)を使用します.
前準備が終わると本命のXDP関連の処理となります.
LoadXdpProg(), LoadAdnAssign()はbpf2goから自動生成されるコードです.
自動生成されるコードについては今回は詳しく触れません.
bpf2goを実行する際に引数として渡す値に基づいてLoad<Name>()生成されます.(今回の場合XdpProgという値を渡したのでLoadXdpProg())
この処理によってXDPのプログラムとマップをロードしてCollect構造体にマッピングします.
var collect = &Collect{}
spec, err := LoadXdpProg()
if err != nil {
panic(err)
}
if err := spec.LoadAndAssign(collect, nil); err != nil {
panic(err)
}
2
3
4
5
6
7
8
引き続いてNICへのアタッチです.
cilium/ebpfにはXDPをNICにアタッチするための関数は用意されていないのでnetlink経由でアタッチします.
netlinkにはXDPをアタッチする関数としてnetlink.LinkSetXdpFd() (opens new window)も用意されています.
今回は明示的にGeneric XDPを指定してアタッチするためにnetlink.LinkSetXdpFdWithFlags (opens new window)を使用しています.
基本的にはnetlink.LinkSetXdpFd()でアタッチして問題ありません.
こちらの記事(Generic XDPを使えばXDP動作環境がお手軽に構築できるようになった (opens new window))にあるようにデフォルトではNative, Genericの順にアタッチが試行されるようです.
以前XDP_REDIRECTを使用する際に明示的にGeneric XDPを指定しなければパケット転送が動作しないというバグを踏んだことがあったため念のため明示的にGeneric XDPを指定しています.
if err := netlink.LinkSetXdpFdWithFlags(link, collect.Prog.FD(), nl.XDP_FLAGS_SKB_MODE); err != nil {
panic(err)
}
defer func() {
netlink.LinkSetXdpFdWithFlags(link, -1, nl.XDP_FLAGS_SKB_MODE)
}()
2
3
4
5
6
アタッチ関連の処理の後はXDPと連動したパケットカウント処理となります.
無限ループとtickerによる1秒感覚の定期処理の中で以下のような処理を行います.
collect.Protocols.Lookup()でBPFマップから値を取り出します.
この時引数にkey, valueの変数のポインタを渡してあげる必要があります.
結果としてマップに値があればvに値が格納されます.
keyに対応する値が存在していなくともerrorは返さないのでこのような記述となっています.
また,今回定義したBPFマップがBPF_MAP_TYPE_PERCPU_ARRAYなのでvは[]uint64型です.
CPUごとにインデックスされて値が格納されるため,今回の実験環境では要素2のスライスとして値が格納されるのでこのような記述となっています.
var v []uint64
var i uint32
for i = 0; i < 32; i++ {
if err := collect.Protocols.Lookup(&i, &v); err != nil {
panic(err)
}
if v[1] > 0 {
fmt.Printf("%s : %v", getProtoName(i), v[1])
} else if v[0] > 0 {
fmt.Printf("%s : %v", getProtoName(i), v[0])
}
}
2
3
4
5
6
7
8
9
10
11
12
以上でpacket_counterは完成です.
パケットをカウントする単純な処理しかしていませんが基本的なXDPのアタッチやマップの定義,参照などは他のプロジェクトでも大体同じ感じです.
# 実行
ビルドして実行してみます.
実験環境はnetns.shを使用して作成します.
ネットワーク構成は以下のような感じです.
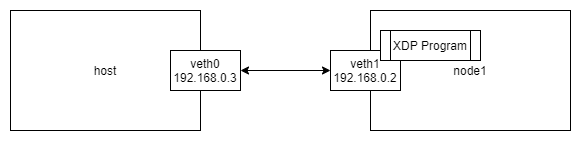
$ sudo ./netns.sh build
$ go generate
$ go build .
2
3
では動かしてみましょう.
XDPプログラムはnode1のnetnsで動かします.
$ sudo ip netns exec node1 ./packet_counter -iface veth1
コンソールが返ってこなければ正常に起動しているはずです.
別のターミナルを起動してveth1のアドレス192.168.0.2に対してpingを飛ばしてみましょう.
$ ping -c 3 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.052 ms
64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.050 ms
64 bytes from 192.168.0.2: icmp_seq=3 ttl=64 time=0.049 ms
--- 192.168.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2033ms
rtt min/avg/max/mdev = 0.049/0.050/0.052/0.001 ms
2
3
4
5
6
7
8
9
このように応答がかえってくるはずです.
ではpacket_counterの画面をみてみます.
IPPROTO_ICMP : 3
このようにICMPパケットが3つカウントされていることがわかります. プロトコルごとにカウントするのでTCPやUDPでも試してみてください.
実験が終了したらnetnsの後片付けをしておきましょう.
$ sudo ./netns.sh clean
# xdp_dump
xdp_dumpはTCPパケットをキャプチャしてダンプするプログラムです.
main.goとbpf/xdp_dump.cから構成されます.
先ほどと同様にXDPとGoに分けてみていきましょう.
# XDP
まずはXDPからです.
ヘッダのインクルードや構造体定義のやり方はpacket_counterと同様です.
今回はBPF_MAP_TYPE_PERF_EVENT_ARRAYを使用します.
BPF_MAP_DEF(perfmap) = {
.map_type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.max_entries = 128,
};
BPF_MAP_ADD(perfmap);
2
3
4
5
さらにperf_event_itemというperfmapに格納する構造体を定義しておきます.
struct perf_event_item {
__u32 src_ip, dst_ip;
__u16 src_port, dst_port;
};
2
3
4
続いてXDP関数の処理を見ていきます.
xdp_dumpという名前で定義しています.
EthernetヘッダやIPv4ヘッダのパースはpacket_counterと同様です.
今回はTCPヘッダもパースするのでその処理を以下に抜粋します.
基本的にやり方は変わりませんが,IPv4ヘッダは可変長なのでip->ihl * 4でヘッダ長を計算して加算してあげる必要があります.
data += ip->ihl * 4;
struct tcphdr *tcp = data;
if (data + sizeof(*tcp) > data_end) {
return XDP_ABORTED;
}
2
3
4
5
その後はSYNフラグがついたパケットのみを対象としてperf eventを発火させます.
packet_sizeはあらかじめdata - data_endで求めています.
プログラム中のコメントにある通り,flagsにはCPUのIDとctx(xdp_md struct)の使用する範囲を指定した値をいれています.
if (tcp->syn) {
struct perf_event_item evt = {
.src_ip = ip->saddr,
.dst_ip = ip->daddr,
.src_port = tcp->source,
.dst_port = tcp->dest,
};
// flags for bpf_perf_event_output() actually contain 2 parts (each 32bit long):
//
// bits 0-31: either
// - Just index in eBPF map
// or
// - "BPF_F_CURRENT_CPU" kernel will use current CPU_ID as eBPF map index
//
// bits 32-63: may be used to tell kernel to amend first N bytes
// of original packet (ctx) to the end of the data.
// So total perf event length will be sizeof(evt) + packet_size
__u64 flags = BPF_F_CURRENT_CPU | (packet_size << 32);
bpf_perf_event_output(ctx, &perfmap, flags, &evt, sizeof(evt));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
その後はXDP_PASSして終了です.
# Go
続いてGoのプログラムを見ていきます.
コマンドライン引数のパース,XDPプログラムやマップのロード,アタッチはpacket_counterと変わらないので省略してperf eventの取り扱いを見ていきます.
XDP側で定義したものと同じフィールドを持つperfEventItem構造体を定義しておきます.
type perfEventItem struct {
SrcIp uint32
DstIp uint32
SrcPort uint16
DstPort uint16
}
2
3
4
5
6
次にperf eventを読むためのReaderを生成します.
perfEvent, err := perf.NewReader(collect.PerfMap, 4096)
goroutineで起動している部分がperf eventをハンドリングする処理部です.
perfEvent.Read()でeventをpollして読み込みます.
無事読み込みが終了した場合event.RawSampleに格納されたバイト列をbinary.Read()でperfEventItem構造体にパースします.
さらに,event.RawSampleがperfEventItemの大きさ(METADATA_SIZE = 12として定義している)よりも大きければパケットデータをダンプしてあげています.
go func() {
var event perfEventItem
for {
evnt, err := perfEvent.Read()
if err != nil {
if errors.Unwrap(err) == perf.ErrClosed {
break
}
panic(err)
}
reader := bytes.NewReader(evnt.RawSample)
if err := binary.Read(reader, binary.LittleEndian, &event); err != nil {
panic(err)
}
fmt.Printf("TCP: %v:%d -> %v:%d\n",
intToIpv4(event.SrcIp), ntohs(event.SrcPort),
intToIpv4(event.DstIp), ntohs(event.DstPort),
)
if len(evnt.RawSample) - METADATA_SIZE > 0 {
fmt.Println(hex.Dump(evnt.RawSample[METADATA_SIZE:]))
}
received += len(evnt.RawSample)
lost += int(evnt.LostSamples)
}
}()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
xdp_dumpではperf eventを使用したためイベント駆動で処理することができました.
# 実行
それでは動かしてみます.
今回もnetns.shで実験環境を作ってプログラムをビルドします.
$ go generate
$ go build .
$ sudo ./netns.sh build
2
3
続いてnode1の中でxdp_dumpを起動しましょう.
起動すると以下のようにTCPのSYNパケットを待ちます.
$ sudo ip netns exec node1 ./xdp_dump -iface veth1
All new TCP connection requests (SYN) coming to this host will be dumped here.
2
3
今回はTCPパケットを扱うので別のターミナルでpythonをつかってHTTPサーバを起動してそこにアクセスしてみます.
$ sudo ip netns exec node1 python3 -m http.server 8888
もう一つターミナルを開いてcurlでHTTPサーバにアクセスしてみましょう.
$ curl http://192.168.0.2:8888
通常通りレスポンスが返ってくると思います.
また,xdp_dumpを動かしているターミナルではTCP(SYN)パケットがダンプされていると思います.
All new TCP connection requests (SYN) coming to this host will be dumped here.
TCP: 192.168.0.3:43910 -> 192.168.0.2:8888
00000000 e2 f7 28 dc a0 65 12 4b fe 5b 64 20 08 00 45 00 |..(..e.K.[d ..E.|
00000010 00 3c 93 c9 40 00 40 06 25 9d c0 a8 00 03 c0 a8 |.<..@.@.%.......|
00000020 00 02 ab 86 22 b8 9c 36 ba 88 00 00 00 00 a0 02 |...."..6........|
00000030 fa f0 81 84 00 00 02 04 05 b4 04 02 08 0a f4 c8 |................|
00000040 ac 0b 00 00 00 00 01 03 03 07 00 00 00 00 00 00 |................|
2
3
4
5
6
7
8
実験が終わったらnetnsを削除しておきましょう.
# basic_firewall
3つめのサンプルはbasic_firewallです.
IPv4ネットワークを入力として与えることで該当した宛先からのパケットをドロップします.
basic_firewall配下のmain.goとbpf/xdp_fw.cから構成されます.
これまでと同様にXDPとGoに分けて見ていきましょう.
# XDP
これまでのサンプルと同様にヘッダのインクルードと構造体の定義を行います.
その後BPFマップの定義を行います.
今回はふたつのマップを定義します.タイプはそれぞれBPF_MAP_TYPE_PERCPU_ARRAY, BPF_MAP_TYPE_LPM_TRIEです.
matchesは通常のArrayです.
入力したルール(IPv4ネットワーク)にマッチしたパケットをカウントするためのマップです.
BPF_MAP_DEF(matches) = {
.map_type = BPF_MAP_TYPE_PERCPU_ARRAY,
.key_size = sizeof(__u32),
.value_size = sizeof(__u64),
.max_entries = MAX_RULES,
};
BPF_MAP_ADD(matches);
2
3
4
5
6
7
blacklistは入力されたルールを保持するマップです.
lpm trieという特殊なマップとして定義します.
lpm trieはLongest Prefix Match with Trie Tree (opens new window)を意味しています.
ルートテーブルなどを作成する際に使用します.
IPv4アドレスとプレフィックスをキー,任意の値をバリューとして保存して使用します.
今回マップの定義にてBPF_F_NO_PREALLOCを指定しています.
BPF_F_NO_PREALLOCはプリアロケーションによるオーバーヘッドを削減するためのフラグです.
詳細は以下のリンクを参照してください.
今回のサンプルではこのフラグを指定しなければBPFマップ作成がInvalid argumentで失敗してしまいました.
これはdropbox/goebpfのサンプル (opens new window)では指定されなくても動作していました.
一方今回cilium/ebpfを使用した際は与える必要がありました.
同様のエラーに遭遇した方は参考にしてください.
BPF_MAP_DEF(blacklist) = {
.map_type = BPF_MAP_TYPE_LPM_TRIE,
.key_size = sizeof(__u64),
.value_size = sizeof(__u32),
.max_entries = MAX_RULES,
.map_flags = BPF_F_NO_PREALLOC,
};
BPF_MAP_ADD(blacklist);
2
3
4
5
6
7
8
さて,マップの定義が終わったのでXDP関数の処理を見ていきます.今回はfirewallという関数名です.
まずはこれまで通りEthernet, IPv4パケットのパースを行います.
その後,blacklistを参照するためのkeyを作成します.
keyはプレフィックスとアドレスのフィールドを持っています.
struct {
__u32 prefixlen;
__u32 saddr;
} key;
key.prefixlen = 32;
key.saddr = ip->saddr;
2
3
4
5
6
7
以下がメインの処理部です.
先ほど用意したkeyでblacklistをlookupしてルールにマッチした場合matchesからもカウンタを取り出してインクリメントしています.
その後,XDP_DROPを返すことでパケットをドロップします.
マッチしなかった場合は単にXDP_PASSを返します.
__u64 *rule_idx = bpf_map_lookup_elem(&blacklist, &key);
if (rule_idx) {
// Matched, increase match counter for matched "rule"
__u32 index = *(__u32*)rule_idx; // make verifier happy
__u64 *counter = bpf_map_lookup_elem(&matches, &index);
if (counter) {
(*counter)++;
}
return XDP_DROP;
}
return XDP_PASS;
2
3
4
5
6
7
8
9
10
11
# Go
次はコントロールプレーンを見ていきます.
コマンドライン引数のパースやXDPプログラムのロードとアタッチはこれまでと同様です.
今回は入力としてドロップするルールを渡します.
また,lpm trieを使用するのでlpmTrieKeyという型を用意しておきます.
type lpmTrieKey struct {
prefixlen uint32
addr uint32
}
2
3
4
この型を使用して入力されたドロップルールをblacklistに挿入します.
for index, ip := range ipList {
fmt.Printf("\t%s\n", ip)
k := ipNetToUint64(createLPMTrieKey(ip))
if err := collect.Blacklist.Put(k, uint32(index)); err != nil {
panic(err)
}
}
2
3
4
5
6
7
以下はパケットのカウントを表示する部分ですpacket_counterで出てきたものとほぼ同じです.
tickerで定期的に処理しています.
for {
select {
case <-ticker.C:
var v []uint64
var i uint32
for i = 0; i < uint32(len(ipList)); i++ {
if err := collect.Matches.Lookup(&i, &v); err != nil {
panic(err)
}
if v[0] != 0 {
fmt.Printf("%18s\t%d\n", ipList[i], v[0])
} else if v[1] != 0 {
fmt.Printf("%18s\t%d\n", ipList[i], v[1])
}
}
fmt.Println()
case <-ctrlC:
fmt.Println("\nDetaching program and exit")
return
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
basic_firewallはBPF_MAP_TYPE_LPM_TRIEを利用することで簡単にIPアドレスがルールにマッチするかどうかを判断することができました.
# 実行
それでは動かしてみます.
今回もこれまでと同様にnetnsで実験環境を用意します.
$ go generate
$ go build .
$ sudo ./netns.sh build
2
3
ではbasic_firewallを起動しましょう.今回は以下のように192.168.0.0/24をブロックするように指定して実行します.
$ sudo ip netns exec node1 ./basic_firewall -iface veth1 -drop 192.168.0.0/24
Blacklisting IPv4 Addresses...
192.168.0.0/24
2
3
4
それでは別のターミナルからpingを飛ばしてみましょう.
192.168.0.3 -> 192.168.0.2向けのパケットが飛ぶはずなのでこれはbasic_firewallを動かしている間はレスポンスがないはずです.
$ ping 192.168.0.2
というわけでbasic_firewallを動かしているターミナルに戻ってみます.
Blacklisting IPv4 Addresses...
192.168.0.0/24
192.168.0.0/24 1
192.168.0.0/24 2
192.168.0.0/24 3
192.168.0.0/24 4
192.168.0.0/24 5
2
3
4
5
6
7
8
9
10
11
12
このようにブロックしたパケットをカウントして出力されています.
Crtl + cでプログラムを終了させるとpingの応答が返ってくるようになることを確認してください.
実験が終了したらnetnsを掃除しておきましょう.
# bpf_redirect_map
4つめのサンプルはbpf_redirect_mapです.
このサンプルはICPMパケットを対象にICMPパケットの送信者にリダイレクトするというものとなっています.
bpf_redirect_map配下のmain.goとbpf/xdp.cから構成されます.
これまでと同様にXDPとGoに分けて見ていきましょう.
# XDP
これまでのサンプルと同様にヘッダのインクルードと構造体の定義を行います. その後BPFマップの定義を行います.
今回はBPF_MAP_TYPE_DEVMAPというタイプのマップを使用します.
このマップはbpf_redirect(), bpf_redirect_map()を使用するためにデバイスのインデックスを保持しておくマップです.
こちらも少しハマりどころがあり,dropbox/goebpfのサンプル (opens new window)ではmax_entriesの値が64となっていますがcilium/ebpfを使用した場合マップに値を入れるときにpanic: update failed: key too big for map: argument list too longと怒られます.
ですので今回は1024という大きめの数字を使用しています.
/* XDP enabled TX ports for redirect map */
BPF_MAP_DEF(if_redirect) = {
.map_type = BPF_MAP_TYPE_DEVMAP,
.key_size = sizeof(__u32),
.value_size = sizeof(__u32),
.max_entries = 1024,
};
BPF_MAP_ADD(if_redirect);
2
3
4
5
6
7
8
次にXDP関数を見ていきます.
関数名はxdp_testです.
これまで通りEthernet, IPv4パケットにパースします.
さらに,IPパケットのプロトコルをみてICMPでなければPASSします.
続いて,ルートテーブルのlookup処理です. XDPではカーネルのルートテーブルを参照することができます. 参照のためには
static int (*bpf_fib_lookup)(void *ctx, void *params, int plen, __u32 flags) = (void*) // NOLINT
BPF_FUNC_fib_lookup;
2
という関数を使用します.
このbpf_fib_lookup()に渡すbpf_fib_lookup構造体の定義について確認します.
struct bpf_fib_lookup {
/* input: network family for lookup (AF_INET, AF_INET6)
* output: network family of egress nexthop
*/
__u8 family;
/* set if lookup is to consider L4 data - e.g., FIB rules */
__u8 l4_protocol;
__be16 sport;
__be16 dport;
/* total length of packet from network header - used for MTU check */
__u16 tot_len;
/* input: L3 device index for lookup
* output: device index from FIB lookup
*/
__u32 ifindex;
union {
/* inputs to lookup */
__u8 tos; /* AF_INET */
__be32 flowinfo; /* AF_INET6, flow_label + priority */
/* output: metric of fib result (IPv4/IPv6 only) */
__u32 rt_metric;
};
union {
__be32 ipv4_src;
__u32 ipv6_src[4]; /* in6_addr; network order */
};
/* input to bpf_fib_lookup, ipv{4,6}_dst is destination address in
* network header. output: bpf_fib_lookup sets to gateway address
* if FIB lookup returns gateway route
*/
union {
__be32 ipv4_dst;
__u32 ipv6_dst[4]; /* in6_addr; network order */
};
/* output */
__be16 h_vlan_proto;
__be16 h_vlan_TCI;
__u8 smac[6]; /* ETH_ALEN */
__u8 dmac[6]; /* ETH_ALEN */
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
ご覧のようにかなりいろいろなフィールドが定義されています. しかし,単なるIPv4ルートテーブルを参照するだけであればそこまで大変ではありません. セットするフィールドは以下です.
- family
- ipv4_src
- ipv4_dst
- ifindex
これらのフィールドをIPパケットとingressのifindexをもとにセットし,bpf_fib_lookup()に渡します.
その結果がfailedでなくno neighでなければルートが引けたことになるのでその結果が引数として渡したfib_paramsに格納されます.
struct bpf_fib_lookup fib_params;
// fill struct with zeroes, so we are sure no data is missing
__builtin_memset(&fib_params, 0, sizeof(fib_params));
fib_params.family = AF_INET;
// use daddr as source in the lookup, so we refleect packet back (as if it wcame from us)
fib_params.ipv4_src = ip_header->daddr;
// opposite here, the destination is the source of the icmp packet..remote end
fib_params.ipv4_dst = ip_header->saddr;
fib_params.ifindex = ctx->ingress_ifindex;
bpf_printk("doing route lookup dst: %d\n", fib_params.ipv4_dst);
int rc = bpf_fib_lookup(ctx, &fib_params, sizeof(fib_params), 0);
if ((rc != BPF_FIB_LKUP_RET_SUCCESS) && (rc != BPF_FIB_LKUP_RET_NO_NEIGH)) {
bpf_printk("Dropping packet\n");
return XDP_DROP;
} else if (rc == BPF_FIB_LKUP_RET_NO_NEIGH) {
// here we should let packet pass so we resolve arp.
bpf_printk("Passing packet, lookup returned %d\n", BPF_FIB_LKUP_RET_NO_NEIGH);
return XDP_PASS;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
ルートが引けたらリダイレクト処理を行います.
IPパケットの宛先と送信元を入れ替えます.
さらにfib_paramsに格納されたdmacとsmacをパケットに上書きします.
そして,
static int (*bpf_redirect_map)(void *map, __u32 key, __u64 flags) = (void*) // NOLINT
BPF_FUNC_redirect_map;
2
を実行してリダイレクトします.
引数には定義したDEVMAPであるif_redirect, それをlookupするキーとしてのifindex, flagは0です.
これによりICMPパケットを送信元にそのままリダイレクトします.
# Go
続いてGoのコントロールプレーンをみていきます.
コマンドライン引数のパースやXDPプログラムのロードとアタッチはこれまでと同様です.
今回はNICを二つ引数として渡してあげます.
bpf2goで自動生成した関数を用いたプログラムのロードはれまでと同様です.
今回のリダイレクトのプログラムは二つのNICにアタッチしなければなりません.
さらに,アタッチするNICのインデックスをDEVMAPに登録する必要があります.
そこで以下のようにAttach()関数を作成して上記の操作をまとめてしまいます.
func Attach(infList []string, prog *ebpf.Program, ifRedirect *ebpf.Map) error {
for _, inf := range infList {
link, err := netlink.LinkByName(inf)
if err != nil {
return err
}
if err := netlink.LinkSetXdpFdWithFlags(link, prog.FD(), nl.XDP_FLAGS_SKB_MODE); err != nil {
return err
}
if err := ifRedirect.Put(uint32(link.Attrs().Index), uint32(link.Attrs().Index)); err != nil {
return err
}
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Detach()も同様に定義しておきdeferに渡しておきます.
そのあとはCtrl + cでの終了処理を行うのみです.
if err := Attach(infList, collect.Prog, collect.IfRedirect); err != nil {
panic(err)
}
defer Detach(infList)
ctrlC := make(chan os.Signal, 1)
signal.Notify(ctrlC, os.Interrupt)
for {
select {
case <-ctrlC:
fmt.Println("\nDetaching program and exit")
return
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 実行
それでは動かしてみましょう.
今回もnetnsで実験を行います.
$ go generate
$ go build .
$ sudo ./netns.sh build
2
3
それでは動かしてみます.
今回は以下のようにこれまでと少し異なる環境を用意しています.

XDPプログラムはnode1でveth1とveth2にアタッチします.
$ sudo ip netns exec node1 ./bpf_redirect_map -iflist veth1,veth2
コンソールが返ってこなければ正常に動作しています.
今回は特に何も出力してくれないので別ターミナルでpingとtcpdumpを使って確認します.
それでは192.168.1.5にpingを飛ばしてみます.その様子をtcpdumpで確認します.
$ ping -c 1 192.168.1.5
まずはbpf_redirect_mapを動かさない状態でパケットを確認します.
# bpf_redirect_mapなし
sudo tcpdump -i veth0 -n -vvv
tcpdump: listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
11:09:49.160300 IP (tos 0x0, ttl 64, id 19056, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.0.3 > 192.168.1.5: ICMP echo request, id 57, seq 1, length 64
11:09:49.160339 IP (tos 0x0, ttl 63, id 13495, offset 0, flags [none], proto ICMP (1), length 84)
192.168.1.5 > 192.168.0.3: ICMP echo reply, id 57, seq 1, length 64
^C
2 packets captured
2 packets received by filter
0 packets dropped by kernel
2
3
4
5
6
7
8
9
10
このようにecho request, replyが一往復みられます.
つぎにbpf_redirect_mapを動かした状態で同様にpingを飛ばしてみます.
$ sudo ip netns exec node1 ./bpf_redirect_map -iflist veth1,veth2
# bpf_redirect_mapあり
sudo tcpdump -i veth0 -n -vvv
tcpdump: listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
11:13:10.304324 IP (tos 0x0, ttl 64, id 29369, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.0.3 > 192.168.1.5: ICMP echo request, id 58, seq 1, length 64
11:13:10.304357 IP (tos 0x0, ttl 64, id 29369, offset 0, flags [DF], proto ICMP (1), length 84)
192.168.1.5 > 192.168.0.3: ICMP echo request, id 58, seq 1, length 64
11:13:10.304493 IP (tos 0x0, ttl 64, id 29370, offset 0, flags [none], proto ICMP (1), length 84)
192.168.0.3 > 192.168.1.5: ICMP echo reply, id 58, seq 1, length 64
11:13:10.304500 IP (tos 0x0, ttl 64, id 29370, offset 0, flags [none], proto ICMP (1), length 84)
192.168.1.5 > 192.168.0.3: ICMP echo reply, id 58, seq 1, length 64
^C
4 packets captured
4 packets received by filter
0 packets dropped by kernel
2
3
4
5
6
7
8
9
10
11
12
13
14
今度は4つパケットがキャプチャされています. ICMPのIDをみてみるとどのパケットも58となっています. 一方で宛先と送信元が入れ替わっているパケットがみられます.
このようにNICからNICへのリダイレクト処理もXDPで行うことができます.
実験終了後にはnetnsをお掃除しましょう.
# おわりに
今回はXDPに入門してみました. だいぶ大作な記事になってしまいました.
XDPの概要やXDPを扱うために必要な周辺知識の紹介,実践編と段階的にXDPを理解できるように書きました. 結構ハマりどころが多い技術なので,私が勉強する際にハマった箇所はできるだけ書き起こしました. XDP関連の日本語の記事はあまり多くないため参考になれば幸いです.
XDPでパケット処理しましょう.
# 参考
# 日本語
- http://gundam-hathaway.net/mecha.html (opens new window)
- Linuxカーネルの新機能 XDP (eXpress Data Path) を触ってみる (opens new window)
- パケットフィルターでトレーシング? Linuxで活用が進む「Berkeley Packet Filter(BPF)」とは何か (opens new window)
- XDPメモ(アーキテクチャ、性能、ユースケース) (opens new window)
- eXpress Data Path (XDP) の概要とLINEにおける利活用 (opens new window)
- パケット処理の独自実装や高速化手法の比較と実践 (opens new window)
- 転びながらもネットワーク処理をソフトウェアで自作していく話 (opens new window)
- Generic XDPを使えばXDP動作環境がお手軽に構築できるようになった (opens new window)
- 今日から始めるXDPと取り巻く環境について (opens new window)
- Go+XDPな開発を始めるときに参考になる記事/janog LT フォローアップ (opens new window)
- ヘッダ構造体メモ (opens new window)
# 英語
- bpf(2) - Linux manual page - man7.org (opens new window)
- bpf-helpers(7) - Linux manual page - man7.org (opens new window)
- XDP - IO Visor Project (opens new window)
- A practical introduction to XDP (opens new window)
- L4Drop: XDP DDoS Mitigations (opens new window)
- Open-sourcing Katran, a scalable network load balancer (opens new window)
- XDP Actions (opens new window)
- BPF In Depth: Communicating with Userspace (opens new window)
- cilium docs bpf #llvm (opens new window)
- How to compile a kernel with XDP support (opens new window)
- Reduce pre-allocation overhead (opens new window)
- cilium/ebpf (opens new window)
- dropbox/goebpf (opens new window)
- vishvananda/netlink (opens new window)