こんにちは.緊急事態宣言が出ているため相変わらず外出ができません.早く収束して欲しいものです. 今回はdocker関連の話題についてです.Googleが開発したgVisorというコンテナランタイムについて調べてみました.
# gVisor
# Documentを意訳
gVisorとはGo言語で実装されたユーザー空間カーネルです.ほとんどのLinuxシステムコールインターフェースを実装しており,ホストOSと起動しているアプリケーションとの間に隔離層を設けることで安全性を実現しています.
gVisorにはrunscというOCI仕様に準拠したコンテナランタイムを含んでいます.runscはDockerやKubernetesで使用でき,簡単にサンドボックス化されたコンテナを実行できます.
gVisorは既存のサンドボックス化ツールと異なるアプローチを用いています.
# Architecture Guide
gVisorは信用されていないコンテナをサンドボックス化する仮想環境を作成します.ホストのカーネルによるシステムインターフェースは攻撃のリスクを少なくするために実装されたユーザー空間カーネルによってラップされます.gVisorは大きなオーバーヘッドはありませんが,リソースの利用に関してプロセスモデルを使用します.
# How is this different?
通常はコンテナを分離する手法としてgVisorとは異なる二つの手法が用いられます.
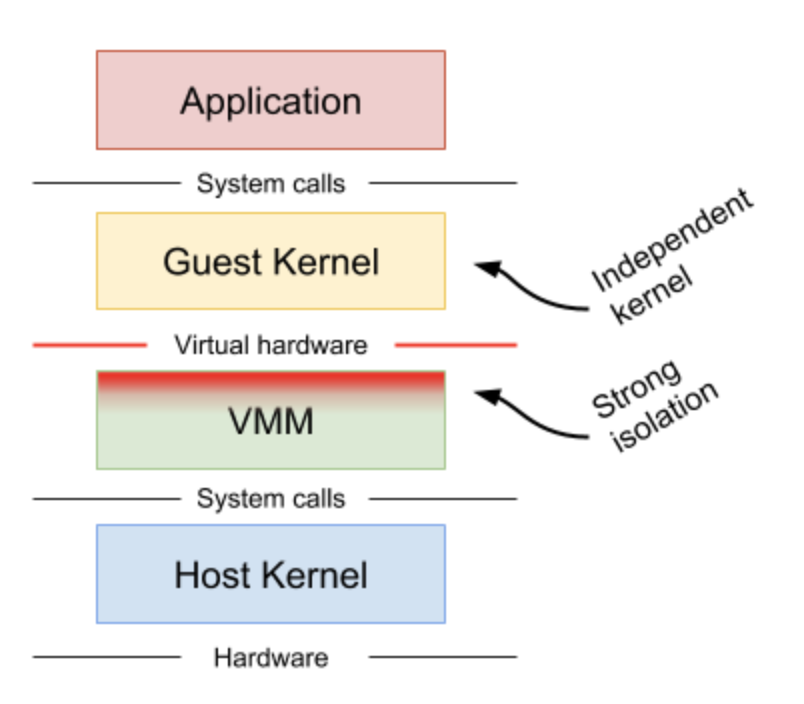
Machine-level virtualization KVMやXenのようなマシンレベルの仮想化はVirtual Machine Monitor(VMM)を経由したゲストカーネルに対して仮想化されたハードウェアをさらしてしまいます.仮想化されたハードウェアは通常軽量化され,追加のメカニズムがゲストとホストの可視性を高めるために使用されます.仮想マシン上で実行されるコンテナは高い分離性や互換性,パフォーマンスを得ることができますが,コンテナにとって追加のプロキシやエージェントを要求されるため,より大きなリソースや起動時間を必要としてしまいます.
Rule-based execution seccompやSELinux, AppArmorのようなルールベースの実行はアプリケーションやコンテナにとって安全な特定のシステムコールのみを実行できます.これらは大抵の場合ルールを強化するためにホストカーネルの内部でフックされます.もしも十分に小さくカーネルの表面が作られているとしたら,この手法はアプリケーションをサンドボックス化し,元のパフォーマンスを維持する良い方法です.しかし,そのポリシーやルールを未知のアプリケーションやコンテナに対して定義するのは難しい場合が多いです.
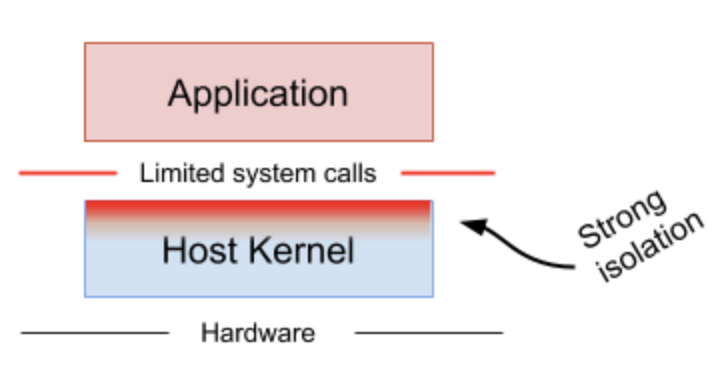 通常,ルールベース実行は多層防御のため追加層を設けます.
通常,ルールベース実行は多層防御のため追加層を設けます.
gVisorはそれらの分離手法と異なり,第三の分離手法をとっています.
gVisorはアプリケーションシステムコールをゲストカーネルとして仮想化ハードウェアを必要とせずに介入します.gVisorはVMMやseccompといったものと同一のように見えます.しかし,このアーキテクチャはより柔軟なリソース管理を行うことができます.一方でこれは互換性の低下やより高いオーバーヘッドをもたらします.
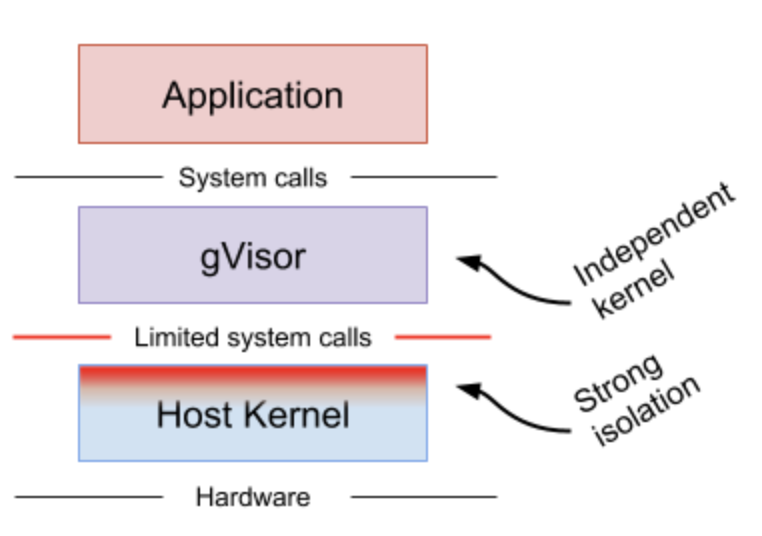 gVisorは多層防御のためにルールベース実行を用います.
gVisorの手法はUser Mode Linux(UML) (opens new window)と似ています.しかし,UMLは内部でハードウェアを仮想化しています.
それぞれの手法は特定の環境では優れています.例えば,マシンレベル仮想化は高い密度を実現するのが困難で,gVisorはシステムコールのパフォーマンスが低いです.
gVisorは多層防御のためにルールベース実行を用います.
gVisorの手法はUser Mode Linux(UML) (opens new window)と似ています.しかし,UMLは内部でハードウェアを仮想化しています.
それぞれの手法は特定の環境では優れています.例えば,マシンレベル仮想化は高い密度を実現するのが困難で,gVisorはシステムコールのパフォーマンスが低いです.
# Why Go?
gVisorは脆弱性を埋め込むことを防ぐためにGo言語で実装されています.
# Overview & Platforms
gVisorのサンドボックスは複数のプロセスから構成されます.これらのプロセスは複数のコンテナを実行できる共有環境を構成します.
それぞれのサンドボックスは隔離されたSentryとGoferというインスタンスを持ちます.
Sentryコンテナを実行し,アプリケーションによって発行されるシステムコールに対して介入し,応答するユーザー空間カーネルGoferコンテナにアクセスするファイルシステムを供給する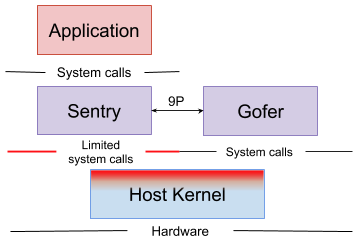
# runsc
サンドボックス化されたコンテナへのエントリーポイントがrunscです.runscはOCI仕様に準拠しています.これはOCI互換のファイルシステムバンドルを実行することができることを意味します.ファイルシステムバンドルはconfig.jsonを含み,コンテナ設定やコンテナのルートファイルシステムから構成されます.
# Sentry
SentryはgVisorの中で最も大きなコンポーネントです.これはユーザー空間カーネルとして動作します.Sentryは信用されていないアプリケーションに必要なカーネルの機能の全てを実装しています.これはほぼ全てのシステムコールやシグナル伝搬,メモリ管理,ページ管理,スレッドなどを実装しています. 信用されていないアプリケーションがシステムコールを発行するとき,使用されているプラットフォームはシステムコールをSentryにリダイレクトします.Sentryはホストカーネルにそのままシステムコールを通すわけではありません.ユーザー空間アプリケーションとして,Sentryはホストのシステムコールを発行します.しかし,Sentryはアプリケーションが自身が発行したシステムコールを直接制御することを許可しません. SentryはLinux v4.4以上の環境が必要です.
サンドボックスにより拡張されたファイルシステムはGoferによって送られます.
# Platforms
gVisorはプラットフォームに対してシステムコールの介入とコンテキストスイッチ,メモリマッピングの機能の実装を要求します.
# ptrace
ptraceはユーザーコードをホストのシステムコールを実行せずに実行するためにPTRACE_SYSEMUを使用します.このプラットフォームはptraceが動作するどんな環境でも実行できます.
# Gofer
Goferは通常のホストLinuxプロセスです.Goferはそれぞれのサンドボックスにより起動され,Sentryに接続されます.Sentryプロセスは制限されたseccompコンテナの中でファイルシステムリソースにアクセスすることなしに起動されます.GoferはSentryに9Pプロトコル経由でファイルシステムリソースにアクセスすることを可能にします.
# Application
アプリケーションはgVisorのOCIランタイムバンドルによって提供される通常のLinuxバイナリです.gVisorはLinux v4.4の環境が必要です.従ってアプリケーションは変更されずに実行できる必要があります.
# gVisorを使ってみる
gVisorを実際に使ってみます.gVisorはLinux環境でしか動作しないので今回はVagrantを用いて仮想環境を用意してその中にDockerを導入します.
リポジトリはこちら.try-gVisor (opens new window)
以下がVagrantfile.
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/xenial64"
config.vm.synced_folder "./docker", "/home/vagrant/work"
config.vm.provision :shell, :path => "./install.sh"
end
2
3
4
5
6
7
起動スクリプトとしてinstall.shを用意します.
#! /bin/sh
sudo apt update
# install docker
sudo apt -y install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt update
sudo apt -y install docker.io
# install gVisor
curl -fsSL https://gvisor.dev/archive.key | sudo apt-key add -
sudo add-apt-repository "deb https://storage.googleapis.com/gvisor/releases release main"
sudo apt-get update && sudo apt-get install -y runsc
sudo systemctl start docker
# add docker user group
sudo groupadd docker
sudo gpasswd -a $USER docker
# config runsc
echo '{
"runtimes": {
"runsc": {
"path": "/usr/bin/runsc"
}
}
}' >> /etc/docker/daemon.json
sudo systemctl restart docker
sudo systemctl enable docker
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
というわけで起動します.
$ vagrant up
起動したらsshで接続します.
$ vagrant ssh
接続したらコンテナをrunscを使用して起動してみましょう.
$ sudo docker run --runtime=runsc -it ubuntu dmesg
[ 0.000000] Starting gVisor...
[ 0.513677] Checking naughty and nice process list...
[ 0.857696] Segmenting fault lines...
[ 1.293455] Creating process schedule...
[ 1.727520] Moving files to filing cabinet...
[ 1.889653] Rewriting operating system in Javascript...
[ 1.976582] Committing treasure map to memory...
[ 2.015297] Preparing for the zombie uprising...
[ 2.486752] Synthesizing system calls...
[ 2.578894] Creating cloned children...
[ 2.677559] Searching for socket adapter...
[ 3.025556] Ready!
2
3
4
5
6
7
8
9
10
11
12
無事起動できたようです.
# gVisorのソースコードを読む
gVisorのリポジトリを手元に落として読んでみます. 今回はGoLandを使用してみました.インターフェースの実装にも飛べるので便利ですね.
# ディレクトリ構成
トップレベルの構成はこんな感じです.
.
├── benchmarks
├── g3doc
├── kokoro
├── pkg
├── runsc
├── scripts
├── test
├── tools
└── vdso
2
3
4
5
6
7
8
9
10
今回はpkgとrunscをみてみます.
# runsc
runscのディレクトリ構成はこちら
.
├── boot
├── cgroup
├── cmd
├── console
├── container
├── criutil
├── debian
├── dockerutil
├── flag
├── fsgofer
├── sandbox
├── specutils
└── testutil
2
3
4
5
6
7
8
9
10
11
12
13
14
とりあえず怪しそうなsandboxパッケージから辿ってみます.
# sandbox
sandboxパッケージにはサンドボックスプロセスを生成するための構造体やメソッドが定義されているようです.
Sandbox wraps a sandbox process. It is used to start/stop sandbox process (and associated processes like gofers), as well as for running and manipulating containers inside a running sandbox. Note: Sandbox must be immutable because a copy of it is saved for each container and changes would not be synchronized to all of them.
type Sandbox struct {
// ID is the id of the sandbox (immutable). By convention, this is the same
// ID as the first container run in the sandbox.
ID string `json:"id"`
// Pid is the pid of the running sandbox (immutable). May be 0 if the sandbox
// is not running.
Pid int `json:"pid"`
// Cgroup has the cgroup configuration for the sandbox.
Cgroup *cgroup.Cgroup `json:"cgroup"`
// child is set if a sandbox process is a child of the current process.
//
// This field isn't saved to json, because only a creator of sandbox
// will have it as a child process.
child bool
// status is an exit status of a sandbox process.
status syscall.WaitStatus
// statusMu protects status.
statusMu sync.Mutex
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Sandbox.Pidがサンドボックスとして動作しているプロセスのPIDのようです.New関数のSandbox.createSandboxProcess()メソッドでプロセスを生成しています.非常に長い関数なので詳細は載せませんが名前空間を指定したり,引数を指定して
func StartInNS(cmd *exec.Cmd, nss []specs.LinuxNamespace) error {
// ...
return cmd.Start()
}
2
3
4
を呼び出します.この関数は内部でcmd.Start()を呼び出してプロセスを生成しているようです.
sandbox.New()を呼び出している箇所を辿ってみるとcontainerパッケージで呼び出されているようです.
# container
続いてcontainerパッケージをみてみます.
type Container struct {
// ID is the container ID.
ID string `json:"id"`
// Spec is the OCI runtime spec that configures this container.
Spec *specs.Spec `json:"spec"`
// BundleDir is the directory containing the container bundle.
BundleDir string `json:"bundleDir"`
// CreatedAt is the time the container was created.
CreatedAt time.Time `json:"createdAt"`
// Owner is the container owner.
Owner string `json:"owner"`
// ConsoleSocket is the path to a unix domain socket that will receive
// the console FD.
ConsoleSocket string `json:"consoleSocket"`
// Status is the current container Status.
Status Status `json:"status"`
// GoferPid is the PID of the gofer running along side the sandbox. May
// be 0 if the gofer has been killed.
GoferPid int `json:"goferPid"`
// Sandbox is the sandbox this container is running in. It's set when the
// container is created and reset when the sandbox is destroyed.
Sandbox *sandbox.Sandbox `json:"sandbox"`
// Saver handles load from/save to the state file safely from multiple
// processes.
Saver StateFile `json:"saver"`
//
// Fields below this line are not saved in the state file and will not
// be preserved across commands.
//
// goferIsChild is set if a gofer process is a child of the current process.
//
// This field isn't saved to json, because only a creator of a gofer
// process will have it as a child process.
goferIsChild bool
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
こちらがContainer構造体.Sandbox, GoferPidといったフィールドを持ってます.container.New()関数内でsandbox.New()関数やContainer.createGoferProcess()メソッドを呼び出しGoferプロセスを生成しているようです.今回はこちらは詳しくみません.
Container構造体にはStart, Run, Executeなどのメソッドが定義されています.
container.New()はpkg/cmdで呼び出されているようです.というわけでcmdパッケージをみてみます.
# cmd
cmdパッケージには各種コマンドが定義されているようです.
cmdパッケージ内のコマンドの名前になってそうな各ファイルの中に構造体が定義してあり,それぞれの構造体はsubcommands.Commandを実装しているようです.subcommandsパッケージはgoogle/subcommands (opens new window)ですね.CLIを作成する際に使用するパッケージのようです.Rustのclapみたいな感じかな.各構造体のExecute()メソッドが実行されるコマンドの実体のようです.cmd/boot.goに定義されているBoot型のBoot.Execute()でサンドボックスが待ち状態で起動するようです.
Boot.Execute()メソッドではLoader構造体を生成してLoader.Run()メソッドを呼び出しているようです.
// Create the loader.
func (b *Boot) Execute(_ context.Context, f *flag.FlagSet, args ...interface{}) subcommands.ExitStatus {
// 省略
bootArgs := boot.Args{
ID: f.Arg(0),
Spec: spec,
Conf: conf,
ControllerFD: b.controllerFD,
Device: os.NewFile(uintptr(b.deviceFD), "platform device"),
GoferFDs: b.ioFDs.GetArray(),
StdioFDs: b.stdioFDs.GetArray(),
Console: b.console,
NumCPU: b.cpuNum,
TotalMem: b.totalMem,
UserLogFD: b.userLogFD,
}
l, err := boot.New(bootArgs)
// 省略
// Run the application and wait for it to finish.
if err := l.Run(); err != nil {
l.Destroy()
Fatalf("running sandbox: %v", err)
}
// 省略
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
Loader.Run()でサンドボックスを起動しているのかな?
Loaderを詳しくみてみましょう.cmd/bootをみてみます.
# boot
bootパッケージに定義されているLoader型を覗いてみます.
// Loader keeps state needed to start the kernel and run the container..
type Loader struct {
// k is the kernel.
k *kernel.Kernel
// ctrl is the control server.
ctrl *controller
conf *Config
// console is set to true if terminal is enabled.
console bool
watchdog *watchdog.Watchdog
// stdioFDs contains stdin, stdout, and stderr.
stdioFDs []int
// goferFDs are the FDs that attach the sandbox to the gofers.
goferFDs []int
// spec is the base configuration for the root container.
spec *specs.Spec
// stopSignalForwarding disables forwarding of signals to the sandboxed
// container. It should be called when a sandbox is destroyed.
stopSignalForwarding func()
// restore is set to true if we are restoring a container.
restore bool
// rootProcArgs refers to the root sandbox init task.
rootProcArgs kernel.CreateProcessArgs
// sandboxID is the ID for the whole sandbox.
sandboxID string
// mu guards processes.
mu sync.Mutex
// processes maps containers init process and invocation of exec. Root
// processes are keyed with container ID and pid=0, while exec invocations
// have the corresponding pid set.
//
// processes is guardded by mu.
processes map[execID]*execProcess
// mountHints provides extra information about mounts for containers that
// apply to the entire pod.
mountHints *podMountHints
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
Loaderのフィールドにはk *kernel.KernelやgoferFDs []intのような気になるフィールドがいくつかあります.
全部見ているとキリがないのでLoader.Run()を覗いてみます.
Loader.Run()はLoader.run()を呼び出しているのでそちらをみます.
func (l *Loader) run() error {
// 省略
return l.k.Start()
}
2
3
4
このメソッドはいろいろな処理をしているようです.気になる関数を列挙してみました.
- Loader.installSeccompFilters()
- createFDTable()
- startGoferMonitor()
startGoferMonitor runs a goroutine to monitor gofer's health. It polls on the gofer FDs looking for disconnects, and destroys the container if a disconnect occurs in any of the gofer FDs.
- processHints()
- CreateProcess()
CreateProcess creates a new task in a new thread group with the given options. The new task has no parent and is in the root PID namespace. If k.Start() has already been called, then the created process must be started by calling kernel.StartProcess(tg). If k.Start() has not yet been called, then the created task will begin running when k.Start() is called. CreateProcess has no analogue in Linux; it is used to create the initial application task, as well as processes started by the control server.
- Loader.Kernel.Start()
こちらも別の機会にみてみたいと思います.
とりあえずKernel.Start()をみてみます.このメソッドはpkg/sentryに定義されているのでpkg/sentryをみてみます.やっとSentryにたどり着きました.
# pkg
ディレクトリ構成はこちら
.
├── abi
├── amutex
├── atomicbitops
├── binary
├── bits
├── bpf
├── buffer
├── compressio
├── context
├── control
├── cpuid
├── eventchannel
├── fd
├── fdchannel
├── fdnotifier
├── flipcall
├── fspath
├── gate
├── gohacks
├── goid
├── ilist
├── linewriter
├── log
├── memutil
├── metric
├── p9
├── pool
├── procid
├── rand
├── refs
├── safecopy
├── safemem
├── seccomp
├── secio
├── segment
├── sentry
├── sleep
├── state
├── sync
├── syncevent
├── syserr
├── syserror
├── tcpip
├── tmutex
├── unet
├── urpc
├── usermem
└── waiter
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# sentry
gVisorの核となるコンポーネント.Sentryでユーザー空間カーネルを実現している.
# kernel
pkg/sentry/kernelにKernel型が定義されています.
Kernel.Start()がこちら.
// Start starts execution of all tasks in k.
//
// Preconditions: Start may be called exactly once.
func (k *Kernel) Start() error {
k.extMu.Lock()
defer k.extMu.Unlock()
if k.globalInit == nil {
return fmt.Errorf("kernel contains no tasks")
}
if k.started {
return fmt.Errorf("kernel already started")
}
k.started = true
k.cpuClockTicker = ktime.NewTimer(k.monotonicClock, newKernelCPUClockTicker(k))
k.cpuClockTicker.Swap(ktime.Setting{
Enabled: true,
Period: linux.ClockTick,
})
// If k was created by LoadKernelFrom, timers were stopped during
// Kernel.SaveTo and need to be resumed. If k was created by NewKernel,
// this is a no-op.
k.resumeTimeLocked()
// Start task goroutines.
k.tasks.mu.RLock()
defer k.tasks.mu.RUnlock()
for t, tid := range k.tasks.Root.tids {
t.Start(tid)
}
return nil
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Task.Start(ThreadID)でタスクを起動しているようです.
このメソッドの処理はこんな感じ.
'tid' must be the task's TID in the root PID namespace and it's used for debugging purposes only (set as parameter to Task.run to make it visible in stack dumps).
func (t *Task) Start(tid ThreadID) {
// If the task was restored, it may be "starting" after having already exited.
if t.runState == nil {
return
}
t.goroutineStopped.Add(1)
t.tg.liveGoroutines.Add(1)
t.tg.pidns.owner.liveGoroutines.Add(1)
t.tg.pidns.owner.runningGoroutines.Add(1)
// Task is now running in system mode.
t.accountTaskGoroutineLeave(TaskGoroutineNonexistent)
// Use the task's TID in the root PID namespace to make it visible in stack dumps.
go t.run(uintptr(tid)) // S/R-SAFE: synchronizes with saving through stops
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
どうやらgoroutineでTask.run(tid)を起動しているようです.
Kernel構造体に登録されているそれぞれのTaskをgoroutineを使用して走らせているようですね.
Task.run()をみてみます.
run runs the task goroutine. threadID a dummy value set to the task's TID in the root PID namespace to make it visible in stack dumps. A goroutine for a given task can be identified searching for Task.run()'s argument value.
func (t *Task) run(threadID uintptr) {
// 省略
for {
t.doStop()
t.runState = t.runState.execute(t)
if t.runState == nil {
t.accountTaskGoroutineEnter(TaskGoroutineNonexistent)
t.goroutineStopped.Done()
t.tg.liveGoroutines.Done()
t.tg.pidns.owner.liveGoroutines.Done()
t.tg.pidns.owner.runningGoroutines.Done()
// Keep argument alive because stack trace for dead variables may not be correct.
runtime.KeepAlive(threadID)
return
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
t.runState = t.runState.execute(t)で実際の処理を行なっていそうです.execute(Task)はインターフェースとして実装されており.runStateの状態により呼び出される実装が変化するようです.今回はrunApp型に実装されているexecute()メソッドをみてみます.
func (app *runApp) execute(t *Task) taskRunState {
// 省略
switch err {
case nil:
// Handle application system call.
return t.doSyscall()
// 省略
}
2
3
4
5
6
7
8
いろいろ処理をしていますがTask.doSyscall()でシステムコールをハンドリングしてそうな感じですね.
doSyscall is the entry point for an invocation of a system call specified by the current state of t's registers. The syscall path is very hot; avoid defer.
func (t *Task) doSyscall() taskRunState {
sysno := t.Arch().SyscallNo()
args := t.Arch().SyscallArgs()
// 省略
// Check seccomp filters. The nil check is for performance (as seccomp use
// is rare), not needed for correctness.
if t.syscallFilters.Load() != nil {
switch r := t.checkSeccompSyscall(int32(sysno), args, usermem.Addr(t.Arch().IP())); r {
// 省略
}
return t.doSyscallEnter(sysno, args)
}
2
3
4
5
6
7
8
9
10
11
12
seccompでシステムコールをチェックしているようです.その後,Task.doSyscallEnter(sysno, args)でシステムコールを発行している感じです.
func (t *Task) doSyscallEnter(sysno uintptr, args arch.SyscallArguments) taskRunState {
if next, ok := t.ptraceSyscallEnter(); ok {
return next
}
return t.doSyscallInvoke(sysno, args)
}
2
3
4
5
6
ptraceSyscallEnter()で発行されるシステムコールがptraceでストップされるべきかチェックした後Task.doSyscallInvoke(sysno, args)を呼び出しています.このメソッドではTask.executeSyscall(sysno, args)を呼び出してシステムコールを発行するようです.このメソッドを覗いてみます.
func (t *Task) executeSyscall(sysno uintptr, args arch.SyscallArguments) (rval uintptr, ctrl *SyscallControl, err error) {
s := t.SyscallTable()
// 省略
if bits.IsOn32(fe, ExternalBeforeEnable) && (s.ExternalFilterBefore == nil || s.ExternalFilterBefore(t, sysno, args)) {
t.invokeExternal()
// Ensure we check for stops, then invoke the syscall again.
ctrl = ctrlStopAndReinvokeSyscall
} else {
fn := s.Lookup(sysno)
// 省略
if fn != nil {
// Call our syscall implementation.
rval, ctrl, err = fn(t, args)
} else {
// Use the missing function if not found.
rval, err = t.SyscallTable().Missing(t, sysno, args)
}
// 省略
return
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
ざっと重要な部分を抜き出しました.最初にシステムコールテーブルを作成してます.その後,テーブルを走査してシステムコールの実体を呼び出しています.(Lookup()の部分)
rval, ctrl, err = fn(t, args)
ここでシステムコールを発行しています.
一通りシステムコールが発行されるまでの流れを追ってみました.大体は追えたかなと思います.というわけで次はユーザー空間システムコールについてみてみます.
先ほどのLookup()から辿ってみます.
// Lookup returns the syscall implementation, if one exists.
func (s *SyscallTable) Lookup(sysno uintptr) SyscallFn {
if sysno < uintptr(len(s.lookup)) {
return s.lookup[sysno]
}
return nil
}
2
3
4
5
6
7
8
SyscallTable型の定義をみてみます.
SyscallTable is a lookup table of system calls. Critically, a SyscallTable is immutable. In order to make supporting suspend and resume sane, they must be uniquely registered and may not change during operation. +stateify savable
type SyscallTable struct {
// 省略
// Table is the collection of functions.
Table map[uintptr]Syscall `state:"manual"`
// lookup is a fixed-size array that holds the syscalls (indexed by
// their numbers). It is used for fast look ups.
lookup []SyscallFn `state:"manual"`
// 省略
}
2
3
4
5
6
7
8
9
10
11
12
lookupフィールドがSyscallFn型のスライスを保持しています.
システムコール関数の登録はRegisterSyscallTable()関数で行われます.
// RegisterSyscallTable registers a new syscall table for use by a Kernel.
func RegisterSyscallTable(s *SyscallTable) {
// Initialize the fast-lookup table.
for num, sc := range s.Table {
s.lookup[num] = sc.Fn
}
}
2
3
4
5
6
7
TableフィールドによりSyscallTable型がNewされる時に初期化されているようです.Tableフィールドはmap[uintptr]Syscall型なので実際に呼び出されるSyscallFn型をマッピングし直しているようです.
Syscall型はこちら
// Syscall includes the syscall implementation and compatibility information.
type Syscall struct {
// Name is the syscall name.
Name string
// Fn is the implementation of the syscall.
Fn SyscallFn
// SupportLevel is the level of support implemented in gVisor.
SupportLevel SyscallSupportLevel
// Note describes the compatibility of the syscall.
Note string
// URLs is set of URLs to any relevant bugs or issues.
URLs []string
}
2
3
4
5
6
7
8
9
10
11
12
13
FnにSyscallFn型を持ってますね.
続いてSyscallFn型をみてみます.
// SyscallFn is a syscall implementation.
type SyscallFn func(t *Task, args arch.SyscallArguments) (uintptr, *SyscallControl, error)
2
名前のごとくシステムコール関数の型ですね.
次はこれらのシステムコール関数の実装を探します.
RegisterSyscallTable(s *SyscallTable)が呼び出される場所を辿ると,runsc/boot/loader_amd64.go, runsc/boot/loader_arm64.goの初期化関数から呼び出されているようです.実装はどちらも同じなので紹介します.(AMDの方)
func init() {
// Register the global syscall table.
kernel.RegisterSyscallTable(linux.AMD64)
}
2
3
4
引数として与えられている構造体をみてみましょう.
AMD64 is a table of Linux amd64 syscall API with the corresponding syscall numbers from Linux 4.4.
var AMD64 = &kernel.SyscallTable{
OS: abi.Linux,
Arch: arch.AMD64,
Version: kernel.Version{
// Version 4.4 is chosen as a stable, longterm version of Linux, which
// guides the interface provided by this syscall table. The build
// version is that for a clean build with default kernel config, at 5
// minutes after v4.4 was tagged.
Sysname: LinuxSysname,
Release: LinuxRelease,
Version: LinuxVersion,
},
AuditNumber: linux.AUDIT_ARCH_X86_64,
Table: map[uintptr]kernel.Syscall{
0: syscalls.Supported("read", Read),
1: syscalls.Supported("write", Write),
2: syscalls.PartiallySupported("open", Open, "Options O_DIRECT, O_NOATIME, O_PATH, O_TMPFILE, O_SYNC are not supported.", nil),
3: syscalls.Supported("close", Close),
4: syscalls.Supported("stat", Stat),
5: syscalls.Supported("fstat", Fstat),
6: syscalls.Supported("lstat", Lstat),
7: syscalls.Supported("poll", Poll),
8: syscalls.Supported("lseek", Lseek),
9: syscalls.PartiallySupported("mmap", Mmap, "Generally supported with exceptions. Options MAP_FIXED_NOREPLACE, MAP_SHARED_VALIDATE, MAP_SYNC MAP_GROWSDOWN, MAP_HUGETLB are not supported.", nil),
10: syscalls.Supported("mprotect", Mprotect),
11: syscalls.Supported("munmap", Munmap),
12: syscalls.Supported("brk", Brk),
13: syscalls.Supported("rt_sigaction", RtSigaction),
14: syscalls.Supported("rt_sigprocmask", RtSigprocmask),
15: syscalls.Supported("rt_sigreturn", RtSigreturn),
16: syscalls.PartiallySupported("ioctl", Ioctl, "Only a few ioctls are implemented for backing devices and file systems.", nil),
// 省略
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
syscalls.Supported()の第二引数に与えられているのがシステムコール関数の実装です.
各システムコールの実装は辿るのが大変なのでまたの機会に.
どのようにSentryとGoferが動いているのかやユーザー空間カーネルについて少しは理解できたかなと思います.
# まとめ
今回はGoogle製の安全なコンテナランタイムであるgVisorを覗いてみました.コンテナプロセスが立ち上がるところから見始めてユーザー空間に実装されたgVisorのシステムコールが実行されるまでを辿ってみました.まだまだわからない部分も多く,飛ばした箇所も多かったので今後もっと詳しくみてみたいです.モチベとしては自作コンテナランタイムとかの足掛かりになればと思っていましたが,そこらへんをみるなら普通にruncとかをみた方がいいかもなと思いました.これはこれで面白かったです.gVisorは現在はLinuxのみのサポートで,ネットワーク周りのオーバーヘッドが大きいということなのでMac OSがサポートされたりパフォーマンスが向上したら実際に使ってみたいなと考えています.